

剪辑|Panda
AI 评审论文,到底靠谱不?
不同的东说念主可能会有不同的谜底,但毫无疑问,东说念主们关于 AI 评审的接受度正在迟缓普及,一些顶级会议也在巨大论文投稿量压力下入手推动此事。举个例子,ICML 2026 就依然放宽了 AI 评审的条件,只是还不允许完全由 AI 推行评审,参阅报说念《评审用无须 AI,作家说了算?ICML 2026 全新评审计策出炉》。
前两天,另一个一样曾被巨量投稿压得喘不外气来的顶级会议 AAAI 2026 也给出了我方的尝试。要知说念,该会议 Main Technical Track 共接收快要 3 万篇投稿,评审工程量十分大。参阅报说念《AAAI-26 投稿量爆炸:近 3 万篇论文,2 万来自中国,评审系统都快崩了》。
具体来说,AAAI 官方合股多所大学和相关机构开展了一份试点相关:为 AAAI-26 会议的每一篇 main-track 投稿都生成了一个 AI 评审扫尾。
至于扫尾,可能在许多东说念主的料到之中:AI 的举座弘扬依然胜过了东说念主类。或者按 AAAI 官方的说法是:「对 AAAI-26 作家和治安委员会成员的大领域拜访骄傲,参与者不仅认为 AI 评审有用,而且在时候准确性和相关提议等要道维度上,内容上更偏好 AI 评审。」

答复标题:AI-Assisted Peer Review at Scale: The AAAI-26 AI Review Pilot
答复地址:https://arxiv.org/abs/2604.13940
底下咱们就来具体望望这份「AAAI-26 AI 评审试点」相关答复。
刻下 AI 领域濒临的评审勤勉
跟着 AI 时候的马上演进,传统的科学同业评审轨制正濒临着前所未有的负荷。非论是 Nature 如故 NeurIPS 等顶尖学术殿堂,连年来的投稿数目都在以惊东说念主的速率激增。
然则,学术界赖以生涯的评审机制却简直停滞不前,重度依赖着东说念主类各人们无偿插足大宗的心血与时辰。
在审稿东说念主资源日益紧缺、资深学者分身乏术的逆境下,保管论文评审的高质料、评判标准的长入性以及出扫尾的时效性,变得越发疲于逃命。
为了顶住 AAAI 2026 创记录的海量投稿,大会组委会以致被逼无奈招募了卓绝 28000 名治安委员会成员,这一领域以致达到了上一届会议的三倍之多!
史无先例的大领域部署:一天内完成两万份深层评审
在这么一个亟需破局的时刻,AAAI 2026 AI 评审试点技俩来了,其长篇答复事无巨细地袒露了他们如安在确切的顶级学术会议高压环境中,诈欺前沿 LLM 对 22977 篇进入全面评审阶段的论文推行了透顶的 AI 审查。
在此前的相关探索中,相关团队往往只可在阻难的模拟环境里,或者是挑选极少依然发表的纯熟论文来测试 AI 的审稿水平。
而这一次的 AAAI 2026 试点筹商,是通盘学术界历史上第一次在大型会议严苛确切切双盲投稿经过中,平直引入且官方部署的 AI 生成式评审体系。
只如果顺利进入 AAAI 2026 评审第一阶段的 22977 篇主流赛说念论文,其作家和评委都会收到一份带有明确 AI 绚丽的评审意见。
会议组委会在实施该筹商时十分严慎地设置了红线:引入 AI 只是为了给通盘经过提供更多维度的附加输入,在此过程中莫得任何一位东说念主类各人的审稿经验被算法所取代。此外,AI 生成的最终文档里弥漫不包含具体的评分数值,也不会给出诸如「接收」或「拒稿」的硬性推选判定。相悖,高等治安委员会成员(SPC)以及领域主席(AC)在作念裁决时,被饱读舞将 AI 挖掘出的问题与东说念主类各人的意见互相印证,玄虚把控论文的质料并决定是否将其推动到第二阶段。
令东说念主深感震荡的是这套 AI 平台展现出的超高扫尾与本钱抵制。
答复给出了明确的算账扫尾:在顶级会议的体量下全面铺开 AI 评审在工程操作上是完全可行且松手的,平摊到每一篇长篇学术论文上的狡计本钱竟然不到 1 好意思元。
值得一提的是,作为这次大会的浩大后盾,OpenAI 为该技俩无偿提供了营救全局的 API 资源补助。在包含复杂代码沙箱与外部搜索接口的多进度责任流中,诈欺刻下处于一活水准的 GPT-5 模子引擎,通盘底层系统在短短不到 24 个小时内就处置结束了全部两万多篇论文的阅读与批改。
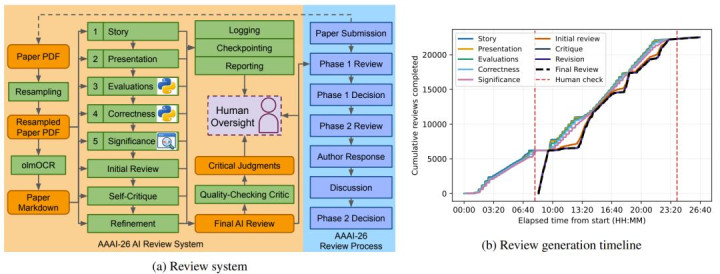
AAAI-26 AI 评审系统和评审生成时辰线
架构剖析:扬弃端到端生成,引入严苛的五步考证轮回
早期的对比相关依然敲响了警钟,如果引诱者图省事,只是通俗地把长篇学术文档丢给大模子并祷告它平直吐出一份详备的审稿意见,得到的芜俚是浮于名义的妄言或者满篇的幻觉。
采纳了这些陶冶后,研发团队经心构建了一条结构繁复、多法子嵌套的 LLM 工业级活水线。
讨论到顶级谈话模子在处置超高辞别率像素图像或异构多模态文档时存在吞吐适度,系统的前置节点会对每一份 PDF 稿件进行长入的标准化预处置。其中总计的插图均会被重新采样至 250 DPI 以相宜显存。由于之前的压力测试暴骄傲纯文本索求方法每每会导致模子倒霉性地误会秘要的数学公式与多级表格,时候团队引入了针对性的 olmOCR,强即将原版 PDF 剥离并调遣为内嵌精确 LaTeX 数学记号以及结构化表格信息的 Markdown 文献。
在同期掌执了 PDF 视觉痕迹与 Markdown 文本之后,AI 评审系统便入手在五个中枢科学审查舱内同期运作 :
故事头绪注视(Story):严格考量作家的问题设定是否成立、文献断层的声明是否确切、中枢孝敬是否站得住脚,并判断文中的笔据链条是否大略语焉不祥。
抒发与结构扫描(Presentation):对行文的明晰度、章节连贯性、语法可读性进行判别,审核复杂的时候语境是否易于同业清醒。
实验评估查对(Evaluations):激活内嵌的 Python 代码解释器,像挑刺一样审查著作采取的对标基线、测试集、统计显赫性筹划,排查营救中枢宗旨的实验是否存在数据纰谬,并专门针对可类似性进行拷问。
正确性推演(Correctness):一样依赖代码沙箱的算力,强行推演并考证复杂的数理公式、逻辑解释、算法伪代码以及图表映射数据的弥漫正确性。
兴趣兴趣兴趣兴趣与行业定位(Significance):授权大模子连入定制的广域网搜索引擎进行跨库文献跟踪。为了属目信息混浊,检索权限被死死为止在相关顶会的厚爱发表文献之中,摒除一切非同业评审的预印本阻挠,借此冷凌弃地评估著作确切切革命幅度并搜寻作家有意规避的对比实验。
当这五大考试兑现后,系统会将洒落的见地重组,排版生成一份体式规整、结构详备的运行审稿草稿。紧接着最要道的一步出现了:系统会启动「自我反省批判」模块。
大模子会被敕令调上路份,死盯着我方刚刚写出的草稿寻找毫无依据的责难、事实层面的误判或者是与原论文凿枘不入的段落。临了,基于自我批判生成的修正清单,大模子会重写并输出最终定稿的 AI 评审答复。总计的底层对话日记、中间现象查验点以及调试答复均被弥远留存,以备东说念主类审计。
在答复最终推送给作家之前,还有一齐基于 GPT-4o-mini 的质料过滤网在静默阻拦。它专门负责筛查文本中是否由于大模子的坚硬而不测流露了匿名的作家身份、是否存在侮辱性词汇、是否夹带了针对性别与地域的系统性偏见,或者结构自身遭到了大肆。唯有给与住这么的打磨,答复身手重睹天日。
在六项要道对比中,东说念主类被 AI 正面打败
非论系统的参数有何等丽都,信得过的裁决权弥远掌执在社区的普遍相关者手中。为了探明这场耗资巨大的试点的内容效用,相关团队向会议的总计利益相关方下发了跟踪问卷,最终告捷回收了 5834 份响应数据。
问卷内置了九大臆测评审质料的硬性黄金标准,kaiyun sports受访者需要在 5 分制的李克特量表上给出他们的评判。
最终的统计图表揭示了一个令传统学者略感不适的本质:在整整九项对照组中,AI 评审在其中六个维度上的中分冷凌弃地超越了由东说念主类学者撰写的答复。
更兴趣兴趣兴趣兴趣的是,相较于抉剔的评审委员,那些被审稿的论文作家群体展现出了对 AI 审查扫尾更强烈的偏疼。
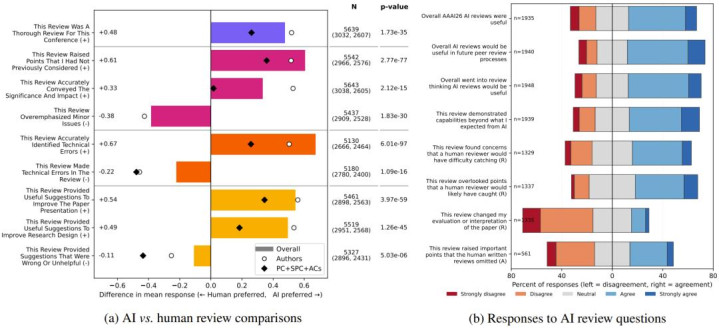
拜访回应:AI 与东说念主工审查对比分析 (a) 及 AI 审核问题 (b)
具体而言,AI 在以下维度展现了压倒性的上风(各项数据的 p-value 均展示出强悍的统计学互异):
在精确锁定深层时候性失误方面,AI 极其明锐(中分最初幅度达到全场最高的 +0.67)。
抛出了作家在撰写时堕入想维盲区、完全未尝顾及的浩大反证(+0.61)。
为诊疗叙述架构和优化论文图表抒发孝敬了实打实的蜕变指南(+0.54)。
就如何修补实验逻辑与强化相关假想输出了树立性的时候意见(+0.49)。
关于 AAAI 这种级别的顶会而言,AI 产出答复的详备与透顶程度让东说念主类小巫见大巫(+0.48)。
虽然,机器当今绝非不成投诚的完东说念主。在剩余的三项考量中,受访者依旧对持东说念主类评委的不凡性。
数据标明,AI 往往容易堕入死巷子,把微不及说念的细枝小节放大成致命问题(过期幅度为 -0.36);在宦囊憨涩中,大模子自身也存在一定的概率写出存在时候纰谬的审稿词(-0.22);而且往畴昔会给出让东说念主啼笑齐非、毫无推行价值的虚空提议(-0.11)。
最终,高达 53.9% 的受访者认为 AI 在这次史诗级的审稿法子中起到了十分故意的作用,而以为机器在帮倒忙的东说念主数仅占总体的 20.2%。更有 61.5% 的从业者示意,他们期待在将来漫长的学术生涯里继续让 AI 参与同业评审。
值赢得味的是,尽管大众在测试前就多情绪预期,依然有 55.6% 的参与者坦承,机器所展现出的时候穿透力依然远远击穿了他们阐明中的 AI 天花板。
舆情聚类知悉:上风与痛点的平直碰撞
跳脱出冷飕飕的打分,相关组还动用高阶大模子对回收的 320 份纯文本主不雅感言进行了当然谈话聚类剖析,提真金不怕火出了刻放学界关于全面引入 AI 的最聚会的五条赞誉以及五大诟病。
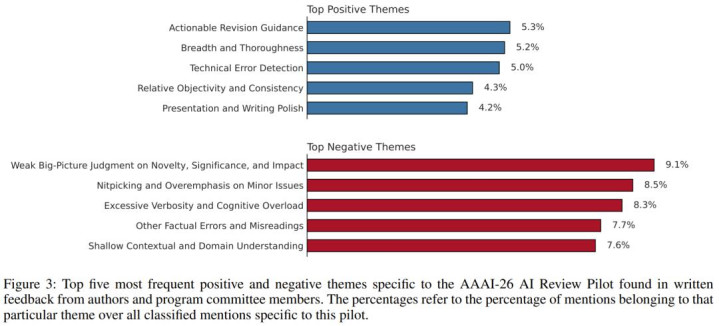
最受追捧的五项正面响应:
直击痛点的修改方略(5.3%):AI 并不单是一味地开炮,它极为擅长将明锐的膺惩马上动荡为逻辑严实、上手可操作的修改撮要。
惊东说念主的阅读广度与精采度(5.2%):机器不存在疲困期,它全场所覆盖每个边角料细节的狂热分析让东说念主类自叹弗如。
时候纰谬拿获器(5.0%):频繁从密密匝匝的推导中精确揪出被几位东说念主类同业接连忽略的公式颠倒。
冰冷的弥漫客不雅(4.3%):AI 不存在学术门派之争,激情弥漫适应,它的介入犹如一齐护城河,灵验稀释了由于个别审稿东说念主带有主不雅偏见或有意打压异己而形成的不公。
语法与版式优化(4.2%):对多样拼写隐患、时态错杂以及图片排版的不规整进行降维打击。
备受责难的五项主要短板:
宏不雅样式与科学感觉极其缺失(9.1%):这是刻下机器不成跳跃的鸿沟。它们在判定一项相关是否具备划时期的行业大肆力或者避讳的巨大科学收益时,每每显得淘气。
钻牛角尖与吹毛求疵(8.5%):芜俚会因为几处不范例的体式而写下宦囊憨涩,导致审稿答复主次倒置,让信得过浩大的逻辑舛讹被澌灭。
信息量溢出激发大脑宕机(8.3%):一份长达数页、包含了几十项细微质疑的答复,内容上极地面增多了被审稿东说念主和审阅主席的处置职守。
倒霉性的事实误读(7.7%):在濒临最前沿的未解领域或者处置繁复的多级张量方程式时,LLM 依然会透顶弄反蓝本的兴趣兴趣。
浅尝辄止的领域底蕴(7.6%):无法作念到像在这个忐忑细分领域苦熬了十多年的各人那样,钩玄纲目塞指出著作与十年前某项不起眼时候的潜在关联。
一位弃取匿名的相关者在响应框中敲下了这么一段话:「我对这套系统的透顶性感到恐惧。它找到了那些容易被东说念主类视觉过滤掉的深层时候空泛,而且绝不繁忙地甩出了最为对口的参考援用。它的冷情保证了莫得主不雅成见。然则,它枯竭一种直观,一种唯有在实验室里泡了无数个昼夜的学者身手领有的灵气。面对那些略微偏离了正宗范式但蕴含着惊东说念主后劲的奇想妙想时,AI 只会古板地打压。」
这位学者临了提议,在将来,应该把文献海选、时候合感性普查这种「脏活累活」全权剥离给机器,从而让东说念主类评委大略专注去品鉴论文的灵魂与对确切寰球的冲击力。
为了确保大模子不是在天花乱坠,团队还抽查了 100 份 AI 生成的答复,诈欺 GPTZero 追查其中的 1356 处外部学术文献援用。
令东说念主赞好意思的是,经过严苛对比,高达 1346 处援用被说明好意思满存在,精确匹配了发表渠说念、挂名作家及原始标题,刺破了所谓 AI 势必放荡产生援用幻觉的坊间听说。
其中那 2 个被检测器用判为伪造的孤例,经东说念主类排查后说明,一个只是援用了企业级未公开诠释书而非学术刊物,另一个则只是是模子搞混了首发的会议缩写。
创立 SPECS 基准:给机器作念一场学术级「病理切片」
光靠问鬈发声还不够硬气。为了用铁证诠释这套复杂的多引擎活水线如实秒杀了平直套壳大模子的泛泛作念法,各人组消费巨资打造了一个名为 SPECS 的变态级科研测谎基准。
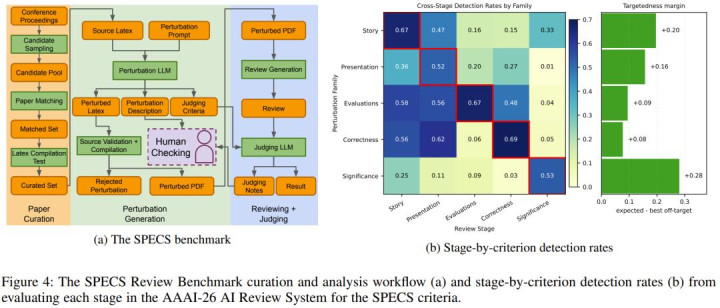
想要通过传统的文本相似度来臆测上万字的绽开式审稿质料无异于痴东说念主说梦。于是,团队参考了也曾的 FLAWS 想路,弃取了主动投毒的策略。他们将眼神锁定了上一届 AAAI 2025 那些依然大放异彩的优秀论文,从中挑选出能在腹地通过底层编译的 LaTeX 原始技俩。紧接着,相关员敕令另一个大模子作为「黑客」,往这些好意思满的论文源码里坏心下毒,精确注入了涵盖故事闹翻、笔墨排版倒霉、实验作假缺失、逻辑公式点窜以及刻意拔喜悦趣兴趣兴趣兴趣这五大维度的「隐性学术癌细胞」。经过重编译后,这批佩戴着致病基因的伪装 PDF 被行动念绝密试卷分发了下来。
在这张布满罗网的试卷上,一头是唯有简约教唆词的通用大模子,另一头则是部署了 AAAI 2026 全套武库的多阶段 AI 系统。作为裁判的更强力模子死死盯着它们交上来的审稿书:唯有在密密匝匝的笔墨中精确点名说念姓地揪出被注入的特定隐患,而且截取出了对应原文作为可信笔据,才算灵验得分。
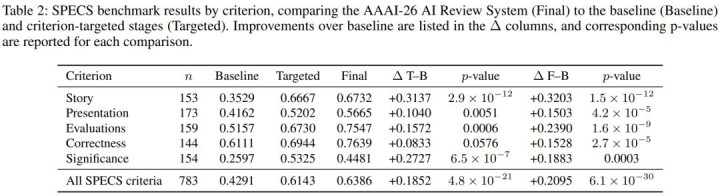
扫尾毫无悬念:单薄的通用基线模子像没头苍蝇一样,在各项纰谬检测上的平均调回率仅有同情的 0.4291。而那套武装到牙齿的最终活水线以碾压之势取得了 0.6386 的惊东说念主战绩,查错效率净普及了 0.20 以上。
非凡是在拆穿「子虚的故事线」以及挖出「实验评估漏报」这两大重灾地,新系统更是如同开了透视外挂,得分狂飙了 0.3203 与 0.2390。这些数据解释:唯有依靠解构、深潜、考证再重塑的高能责任流,身手信得过逼出 LLM 的科学推理极限。
结语
通读这份 AAAI 2026 AI 评审试点回来,咱们大略捕捉到一个明肯定号:诈欺刻下位居行业偏执的多模态大模子矩阵来协管浑沌的科学文献评审,在时候推行面上不仅绰绰过剩,而且如实大略以更低本钱为堕入泥潭的学术圈带来巨大的杠杆效应。
虽然,这绝不虞味着咱们不错行所无忌地交出场所盘。
在热烈的争论中,一部分学者基于原则发出了最严厉的告诫。他们忧虑地指出,如果对这种力量不加节制,AI 的过度渗入将会不成逆转地腐蚀掉同业评审这一轨制背后最可贵的东说念主性温度与学界信任左券。
更有从业者预言,这种便利可能会温水煮青蛙一般,使得新一代评审委员退化掉本该明锐的学术感觉;同期这也将倒逼论文作家们罢休追求说念理的初志,转而破耗大把元气心灵去钻研如何修改排版以夤缘 AI 的隐性偏好。
更有甚者担忧,大模子宦囊憨涩的答复极具魅惑力,极易让那些想要偷懒的主席在莫得切身下场阅读的情况作念出余勇可贾的失误裁决。
但历史的车轮滔滔上前。问卷数据以及广宽的引诱者日记都在反复佐证一个事实:机器的硅基心智与东说念主类的碳基贤达,注定要在将来的科学前沿愈加密不成分。
你的 AAAI 2026 论文收到了若何的 AI 评审?开云体育官方网站
大发官方网站手机app 备案号:
备案号: